The possibility to crawl your website to store and analyze its contents in Elasticsearch can be incredibly useful for search, analytics, or monitoring purposes. In this post, we’ll cover two methods to do this:
- Using Elastic Cloud’s web crawler (ideal for those who want a no-code solution).
- Building a custom Python web crawler that can extract and index your website content into Elasticsearch.
Let’s dive into both methods.
Table of contents
Using Elastic Cloud’s Web Crawler
Elastic Cloud offers a built-in web crawler that makes it easy to scrape content from your website and store it in an Elasticsearch index. Here’s how you can set it up:
Your Elasticsearch Instance
First, create an Elasticsearch instance in Elastic Cloud if you haven’t already. Ensure you have an active deployment with access to Kibana.
Enable the Web Crawler in Kibana
Once inside Kibana, navigate to the Enterprise Search tab:
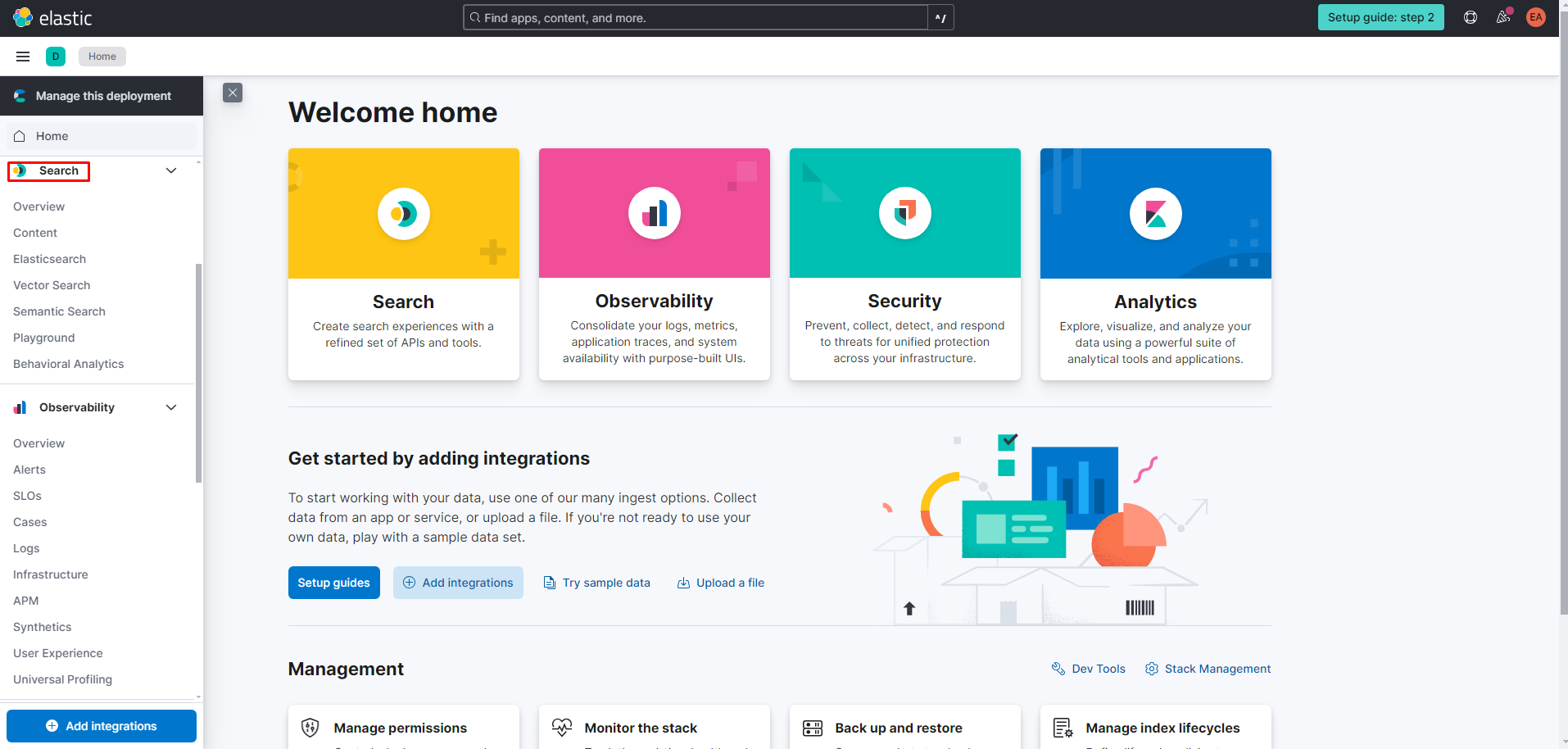
Once in Search, select the Web Crawlers section, you’ll be able to create a new crawler configuration.
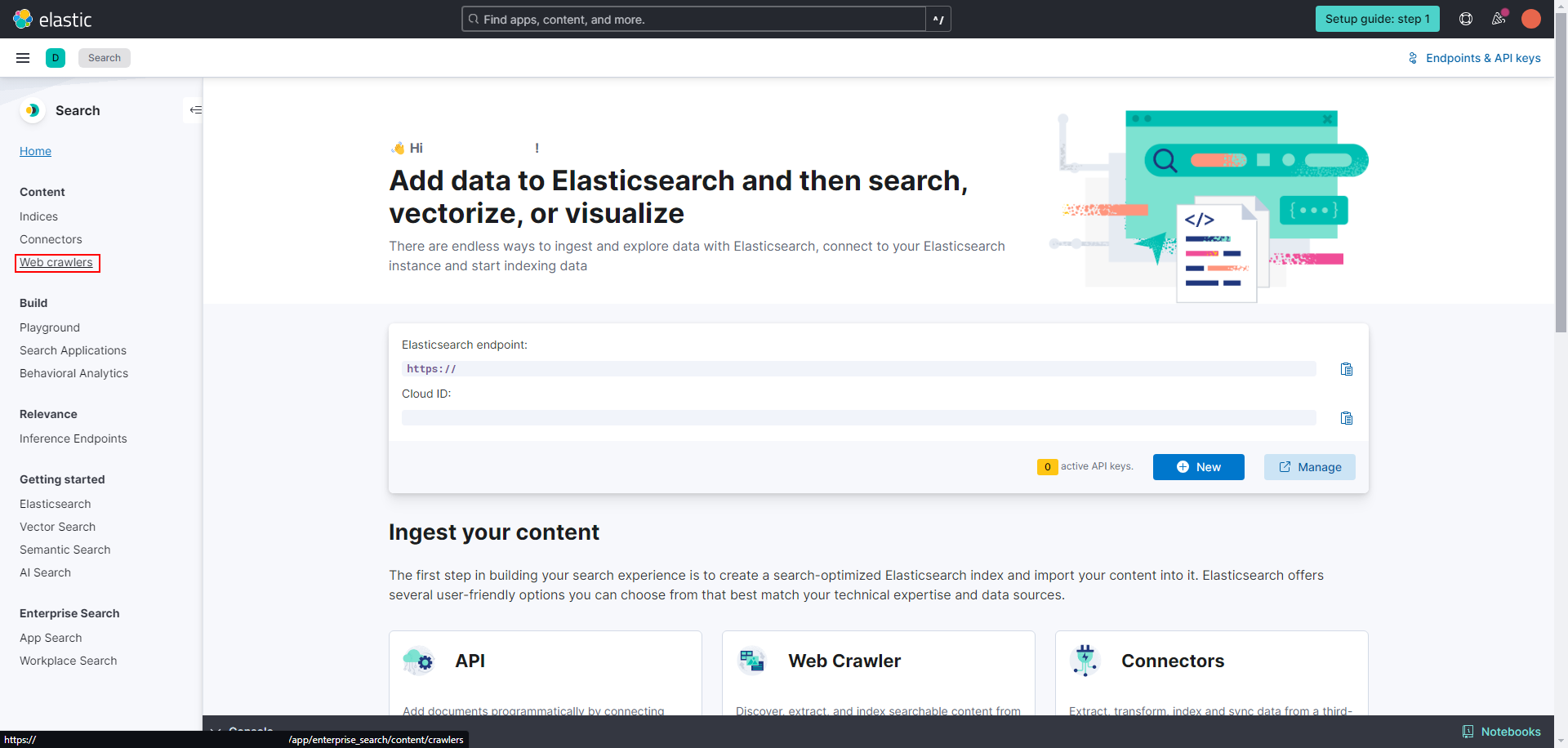
After entering on web crawlers, let’s go ahead and create a new one for our website. You can insert whichever name you want for the index that will store the info of our website:
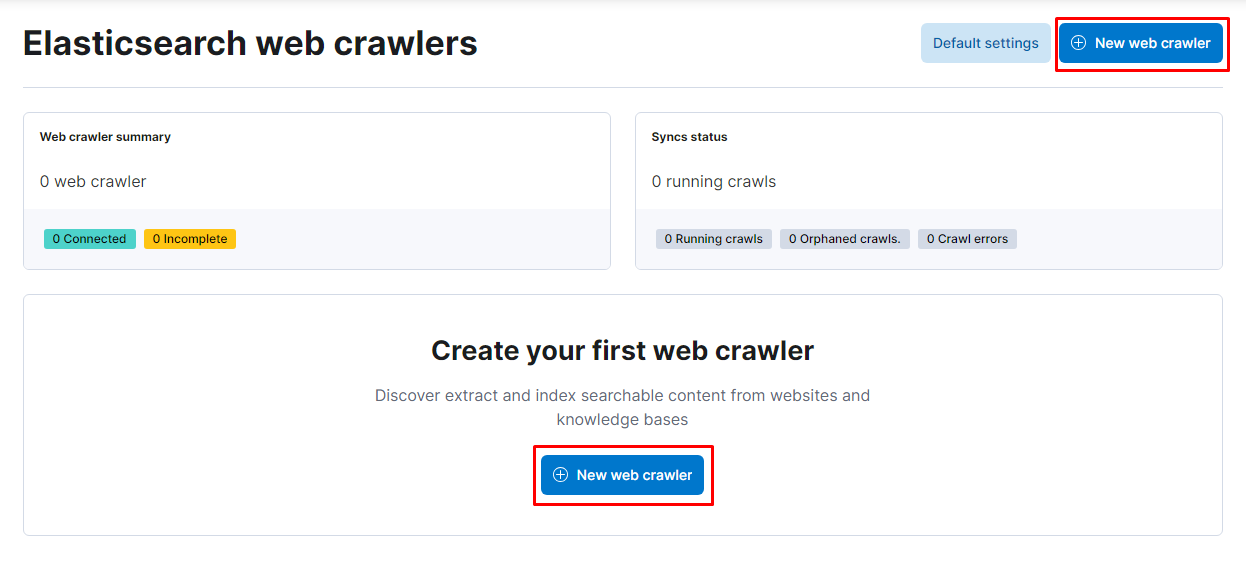
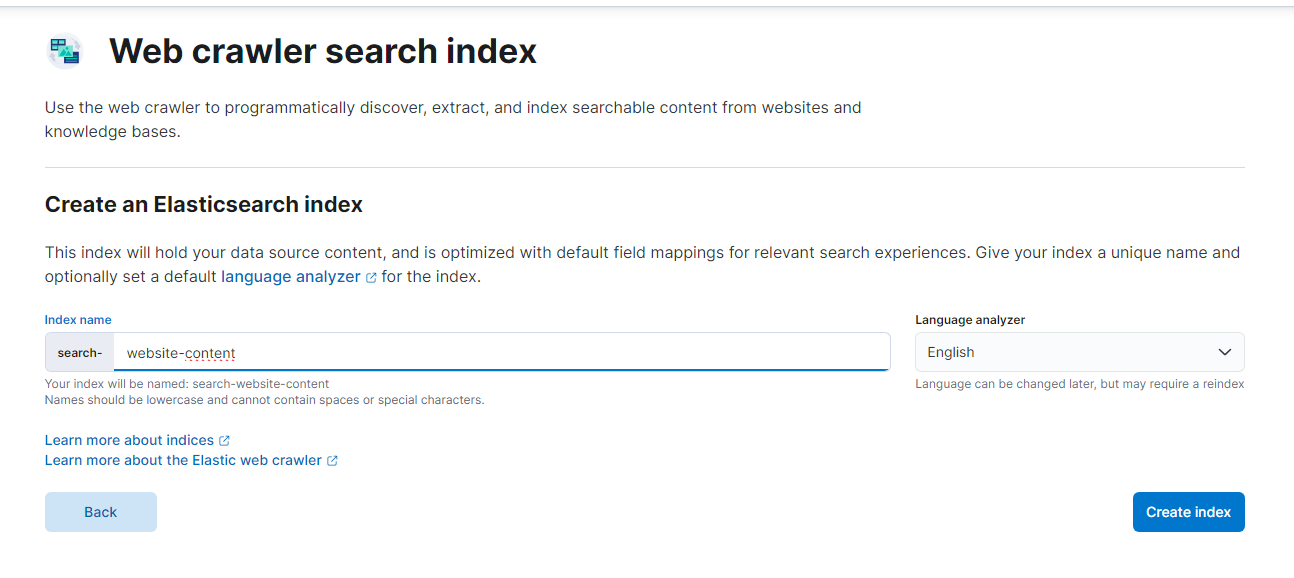
Now, let’s add in our domain:
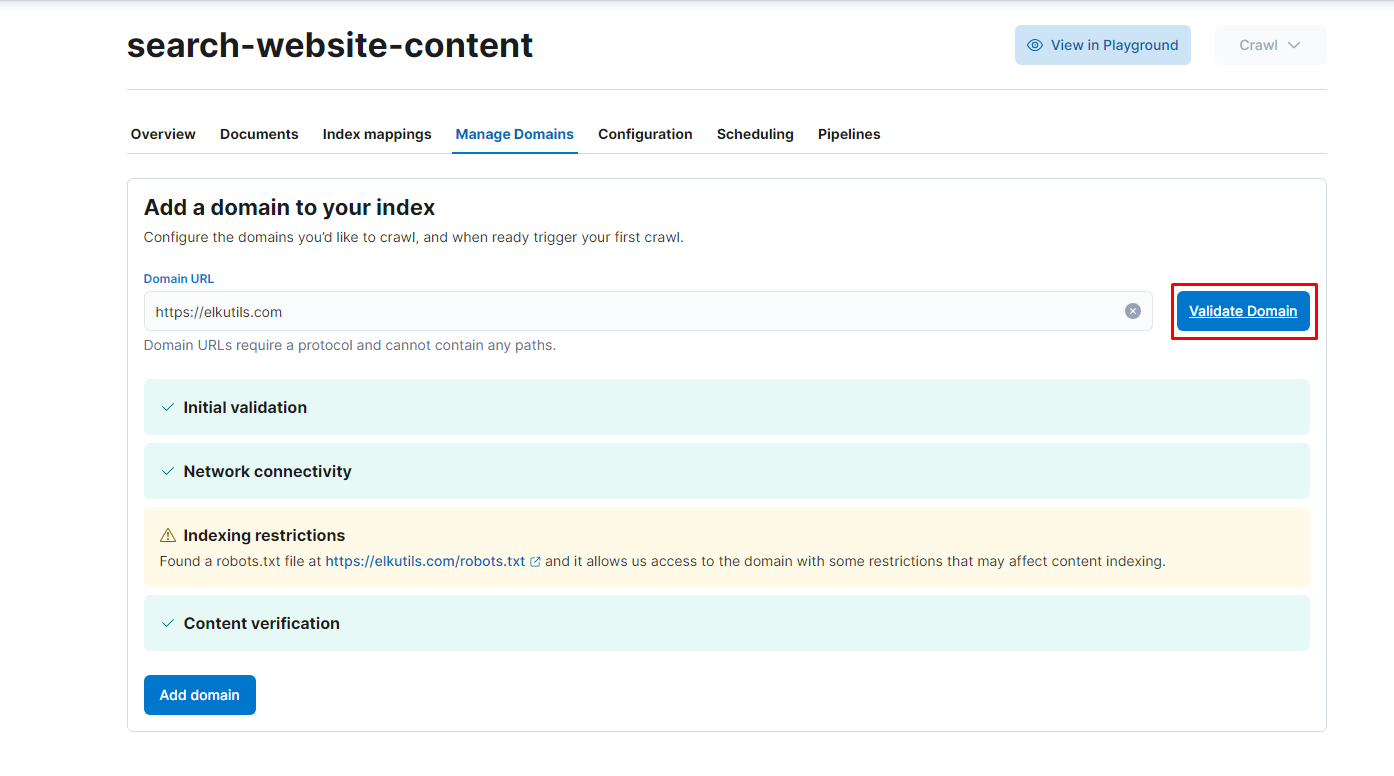
If you wish, you may add more entrypoints for the crawler to obtain the remaining of the data that you need. Nonetheless, when you are ready, all that it’s left is to do is to crawl our website!
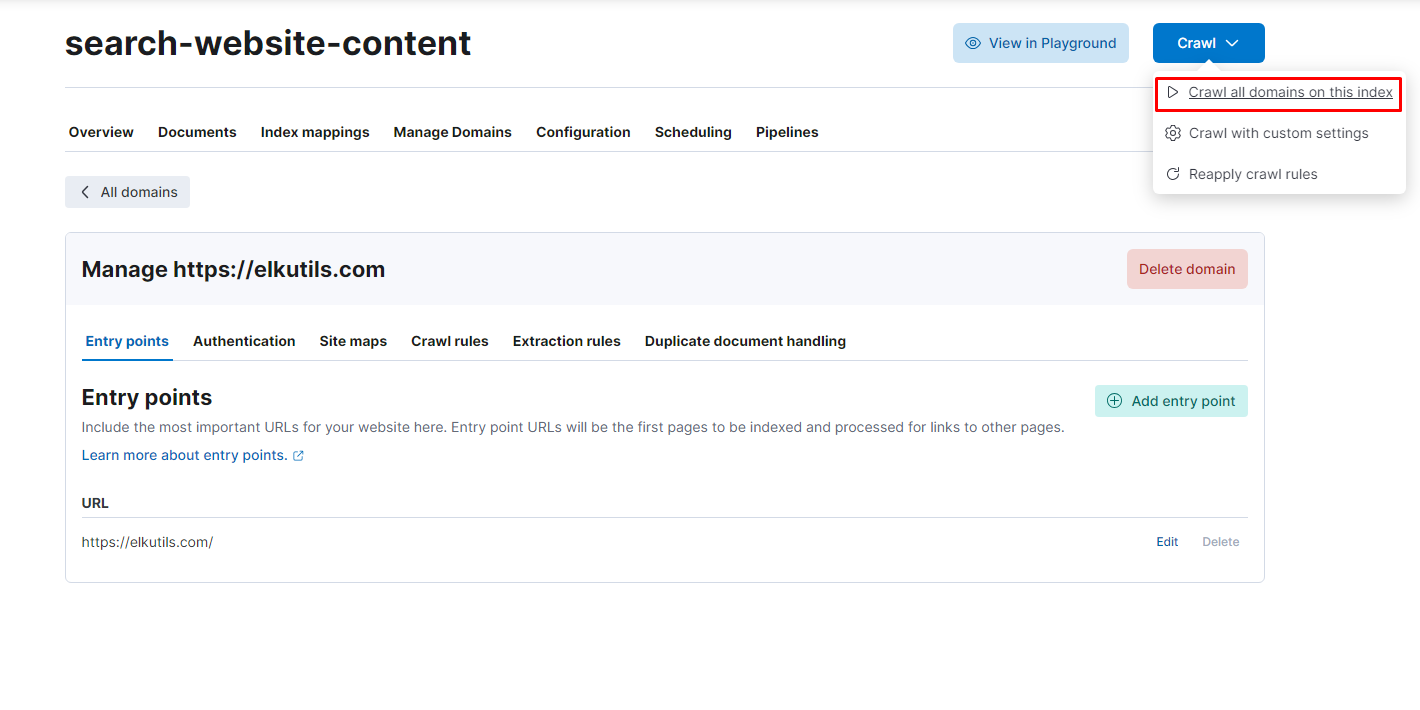
Checking the results
To check if everything went smoothly, we can go to the developer console and check the documents that were indexed by the crawler we configured previously, by using the query below:
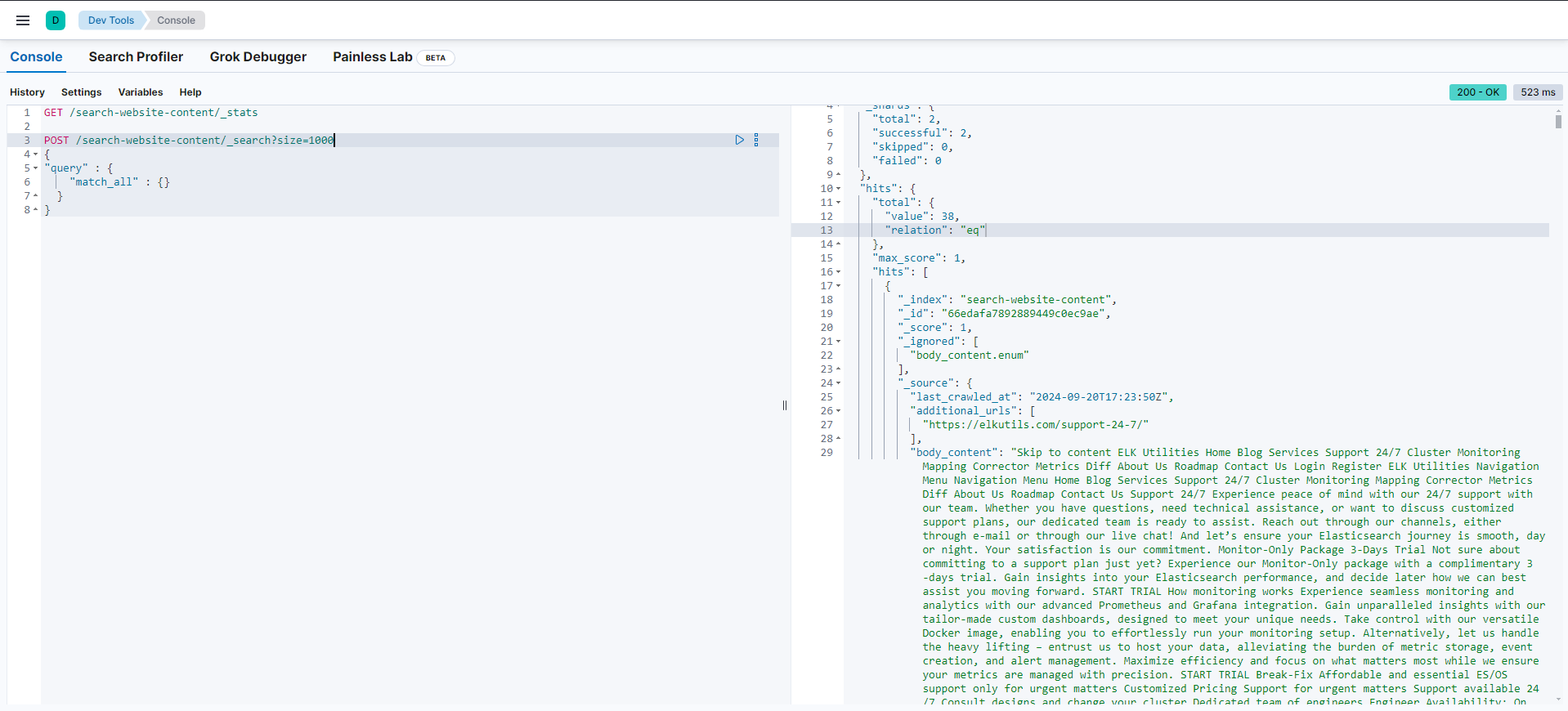
And that concludes the Elastic Cloud method!
Building a Python Web Crawler (Step-by-Step)
In this guide, we’ll develop a Python script from scratch to crawl your website and index the content into Elasticsearch. We’ll explain each step and build the script incrementally.
Prerequisites
- Python 3.x installed on your system.
- Basic knowledge of Python programming.
- An Elasticsearch instance running (local or cloud-based).
- Required Python libraries:
requestsbeautifulsoup4elasticsearch
You can install the necessary libraries using pip:
pip install requests beautifulsoup4 elasticsearch
Import Necessary Libraries
First, we’ll import all the libraries we’ll need for the script.
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, urljoin, urldefrag
from elasticsearch import Elasticsearch
from datetime import datetime
- requests: To make HTTP requests to web pages.
- BeautifulSoup: To parse and extract data from HTML content.
- urllib.parse: To manipulate URLs.
- elasticsearch: To interact with Elasticsearch.
- datetime: To timestamp the crawled data.
Initialize Variables and Elasticsearch Client
Set up the base URL of your website and initialize the Elasticsearch client.
# Initialize values
base_url = "https://your-website-here.com"
# Replace with your Elasticsearch credentials and URL
client = Elasticsearch('your-elasticsearch-uri',
basic_auth=('your-username', 'your-password')
)
- ase_url: The starting point of your crawl.
- client: The Elasticsearch client used to index data.
Note: Replace 'your-elasticsearch-uri', 'your-username', and 'your-password' with your actual Elasticsearch details.
Set Up Headers
Define headers to mimic a real browser request, which helps in bypassing any basic anti-crawling measures.
# Headers to simulate a browser visit
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)'
}
Initialize Data Structures
Set up data structures to keep track of visited URLs, the queue of URLs to visit, and the data to submit to Elasticsearch.
# Sets to keep track of URLs
visited_urls = set()
url_queue = []
data_to_index = []
- isited_urls: Keeps track of already visited URLs to avoid duplicates.
- url_queue: A list acting as a queue for URLs to crawl.
- data_to_index: Stores the extracted data to be indexed.
Perform the Initial Crawl
We need a function to collect all the URLs from the initial page and add them to the queue. This allows us to explore the website starting from the base URL.
def initial_crawl(base_url):
response = requests.get(url=base_url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
a_links = soup.find_all('a')
for link in a_links:
href = link.get('href') # Use .get() to safely extract the href attribute
if href:
# Join the base URL and relative URLs
full_url = urljoin(base_url, href)
# Remove the fragment (part after #) from the URL
full_url, _ = urldefrag(full_url)
# Remove trailing slash unless it's the root URL
if full_url.endswith('/') and full_url != base_url.rstrip('/'):
full_url = full_url.rstrip('/')
urls.add(full_url)
# Convert the set to a list (optional)
return list(urls)
a. Extract Links and Headings
Create a function to extract all the headings and links from a page:
def extract_links_and_headings(soup, base_url):
links = []
headings = []
for heading_tag in ['h1', 'h2', 'h3', 'h4', 'h5', 'h6']:
headings += [h.get_text(strip=True) for h in soup.find_all(heading_tag)]
for a in soup.find_all('a', href=True):
full_url = requests.compat.urljoin(base_url, a['href'])
links.append(full_url)
return headings, links
This function crawls the base URL and extracts all the links on the page. It stores unique URLs in the urls set and returns a list of them. We’ll expand on this in the next step.
b. Extract Page Metadata
Create a function to extract metadata and content from a page:
def extract_page_metadata(content, url):
soup = BeautifulSoup(content, 'html.parser')
parsed_url = urlparse(url)
meta_desc = soup.find('meta', attrs={'name': 'description'})
meta_description = meta_desc['content'] if meta_desc else None
title = soup.title.string if soup.title else None
body_content = soup.get_text(separator=' ', strip=True)
headings, links = extract_links_and_headings(soup, url)
page_info = {
"last_crawled_at": datetime.now().isoformat(),
"body_content": body_content,
"domain": parsed_url.netloc,
"title": title,
"url": url,
"url_scheme": parsed_url.scheme,
"meta_description": meta_description,
"headings": headings,
"links": links,
"url_port": parsed_url.port,
"url_host": parsed_url.hostname,
"url_path": parsed_url.path
}
a_links = soup.find_all('a')
for link in a_links:
href = link.get('href')
if href:
full_url = urljoin(base_url, href)
full_url, _ = urldefrag(full_url)
if full_url.endswith('/') and full_url != base_url.rstrip('/'):
full_url = full_url.rstrip('/')
if full_url not in urls:
print(f'Adding {full_url} in the queue')
queue.append(full_url)
urls.add(full_url)
return page_info
This function takes the raw HTML content of a page and parses it using BeautifulSoup. It extracts the page’s metadata, like the title, meta description, and text content. This data is stored in a dictionary that we’ll later submit to Elasticsearch.
Implement the Crawl Logic
Now, we need to implement the crawling logic. This involves adding URLs to the queue, extracting metadata from each page, and recursively discovering more URLs to crawl:
def begin_crawl(base_url):
queue.extend(initial_crawl(base_url))
while True:
# Once queue ends, end while loop
if len(queue) == 0:
break
# Verify if we are going to scrape our own website, otherwise skip
parsed_url = urlparse(queue[0])
if parsed_url.hostname != urlparse(base_url).hostname:
queue.pop(0)
continue
print(f'Requesting {queue[0]}...')
# Extract content from pages (headings, links, etc)
response = requests.get(url=queue[0], headers=headers)
data_to_submit.append(extract_page_metadata(response.content, queue[0]))
print(f'{queue[0]} done!')
queue.pop(0)
return data_to_submit
Here’s how this works:
- We begin by calling
initial_crawlto populate the queue with URLs. - The
whileloop continues to process URLs from the queue. - Each page is crawled, its metadata is extracted, and additional links found on the page are added to the queue for future crawling.
In this section, we loop through the list of crawled data (data_to_submit) and index each page into the Elasticsearch index (website-content). Replace 'website-content' with the index name of your choice.
Index the Data into Elasticsearch
After we’ve crawled the pages and gathered their metadata, the final step is to index this data into Elasticsearch.
# Start crawling and submit data to Elasticsearch
if __name__ == "__main__":
data = begin_crawl(base_url)
for doc in data:
print(f'Indexing {doc["url"]}')
client.index(index='website-content', document=doc)
print("Crawling and indexing complete!")
Final Script
When combined, here’s the final Python script to crawl your website and index the contents into Elasticsearch:
import requests
from bs4 import BeautifulSoup
from urllib.parse import urlparse, urljoin, urldefrag
from elasticsearch import Elasticsearch, helpers
from datetime import datetime
# Init values
base_url = "https://your-website-here"
client = Elasticsearch('your-elasticsearch-uri',
basic_auth=('your-user',
'your-password')
)
# Necessary in order to bypass moderation
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.12; rv:55.0) Gecko/20100101 Firefox/55.0',
}
urls = set()
queue = []
data_to_submit = []
def extract_links_and_headings(soup, base_url):
links = []
headings = []
for heading_tag in ['h1', 'h2', 'h3', 'h4', 'h5', 'h6']:
headings += [h.get_text(strip=True) for h in soup.find_all(heading_tag)]
for a in soup.find_all('a', href=True):
full_url = requests.compat.urljoin(base_url, a['href'])
links.append(full_url)
return headings, links
def extract_page_metadata(content, url):
soup = BeautifulSoup(content, 'html.parser')
parsed_url = urlparse(url)
# Extract meta description
meta_desc = soup.find('meta', attrs={'name': 'description'})
meta_description = meta_desc['content'] if meta_desc else None
# Extract title
title = soup.title.string if soup.title else None
# Extract body content
body_content = soup.get_text(separator=' ', strip=True)
# Extract headings and links
headings, links = extract_links_and_headings(soup, url)
# Create a data dictionary
page_info = {
"last_crawled_at": datetime.now().isoformat(),
"body_content": body_content,
"domain": parsed_url.netloc,
"title": title,
"url": url,
"url_scheme": parsed_url.scheme,
"meta_description": meta_description,
"headings": headings,
"links": links,
"url_port": parsed_url.port,
"url_host": parsed_url.hostname,
"url_path": parsed_url.path
}
#adding to queue
a_links = soup.find_all('a')
for link in a_links:
href = link.get('href') # Use .get() to safely extract the href attribute
if href:
# Join the base URL and relative URLs
full_url = urljoin(base_url, href)
# Remove the fragment (part after #) from the URL
full_url, _ = urldefrag(full_url)
# Remove trailing slash unless it's the root URL
if full_url.endswith('/') and full_url != base_url.rstrip('/'):
full_url = full_url.rstrip('/')
if full_url not in urls:
print(f'Adding {full_url} in the queue')
queue.append(full_url)
urls.add(full_url) # Add the normalized URL to the set
return page_info
def initial_crawl(base_url):
response = requests.get(url=base_url, headers=headers)
soup = BeautifulSoup(response.content, 'html.parser')
a_links = soup.find_all('a')
for link in a_links:
href = link.get('href') # Use .get() to safely extract the href attribute
if href:
# Join the base URL and relative URLs
full_url = urljoin(base_url, href)
# Remove the fragment (part after #) from the URL
full_url, _ = urldefrag(full_url)
# Remove trailing slash unless it's the root URL
if full_url.endswith('/') and full_url != base_url.rstrip('/'):
full_url = full_url.rstrip('/')
urls.add(full_url)
# Convert the set to a list (optional)
return list(urls)
def begin_crawl(base_url):
queue.extend(initial_crawl(base_url))
while True:
# Once queue ends, end while loop
if len(queue) == 0:
break
# Verify if we are going to scrape our own website, otherwise skip
parsed_url = urlparse(queue[0])
if parsed_url.hostname != urlparse(base_url).hostname:
queue.pop(0)
continue
print(f'Requesting {queue[0]}...')
# Extract content from pages (headings, links, etc)
response = requests.get(url=queue[0], headers=headers)
data_to_submit.append(extract_page_metadata(response.content, queue[0]))
print(f'{queue[0]} done!')
queue.pop(0)
return data_to_submit
# Start crawling and submit data to Elasticsearch
if __name__ == "__main__":
data = begin_crawl(base_url)
for doc in data:
print(f'Indexing {doc["url"]}')
client.index(index='website-content', document=doc)
print("Crawling and indexing complete!")
Checking the results
To check if everything went smoothly, we can go to the developer console and check the documents that were indexed by the crawler we configured previously, by using the query below:
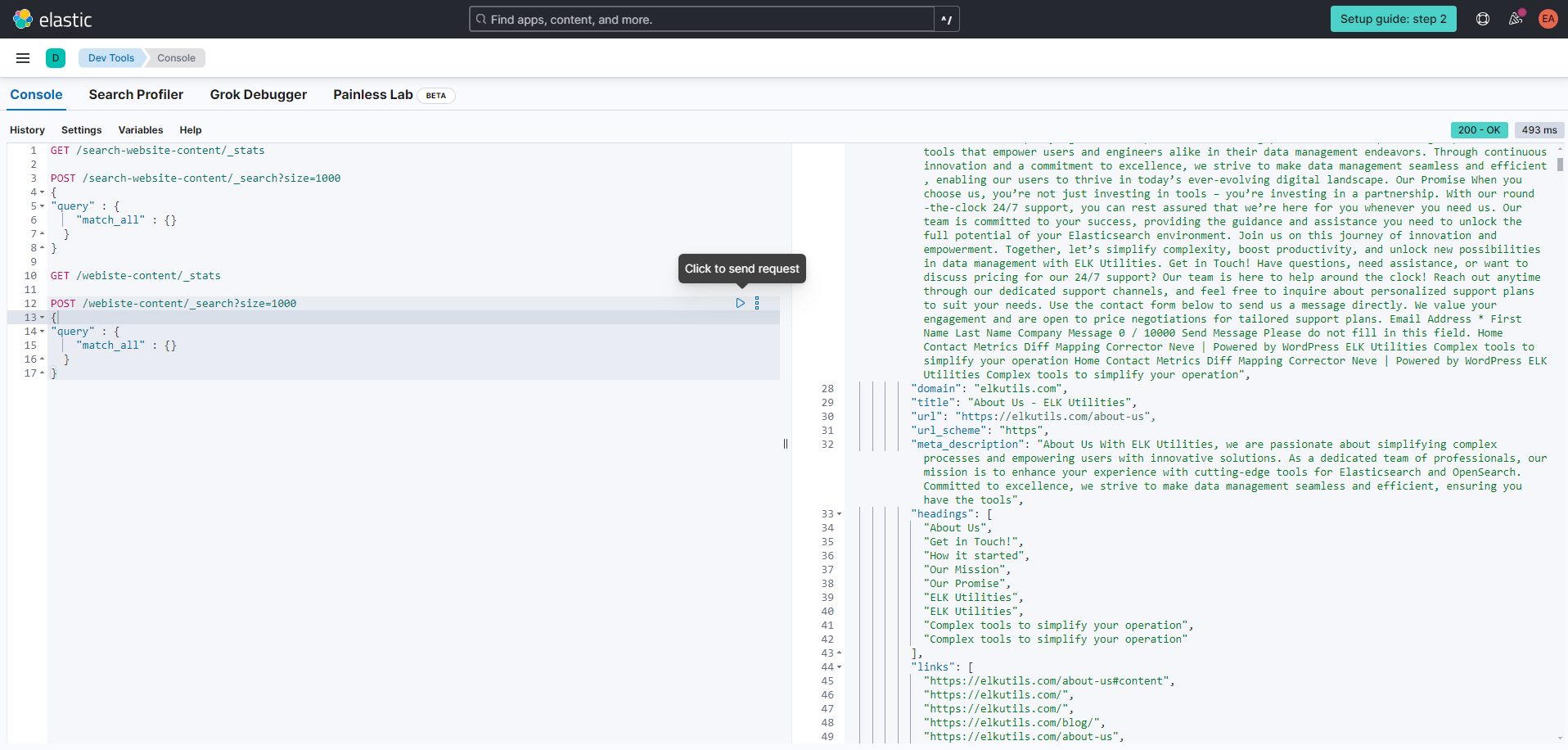
Conclusion
In this blog post, we’ve explored two effective methods for crawling and indexing website content into Elasticsearch. First, we discussed Elastic Cloud’s web crawler, a convenient option for those who prefer a managed solution. Then, we dove into a step-by-step guide to building your own Python web crawler, capable of extracting page metadata and storing it in Elasticsearch.
Whether you’re looking to index a small personal website or manage large-scale content ingestion, these techniques can be tailored to suit your needs. The Python script we developed offers flexibility and control over the crawling process, allowing you to customize how data is gathered and indexed.
By leveraging the power of Elasticsearch, you can turn your website’s content into a searchable index, making it easier to analyze and retrieve information in real-time.