Despite using Elasticsearch in various applications—from powering search engines to analyzing log data—we often take for granted the sophisticated algorithms working behind the scenes to deliver the most relevant results. While it’s easy to overlook, the importance of these algorithms, especially BM25, cannot be overstated. They are the driving force behind how documents are scored and ranked, directly impacting the effectiveness of every search.
In this blog post, we will delve into BM25, the default ranking algorithm used by Elasticsearch. We’ll break down the math that powers it, show how it influences search results, and explain how you can tweak its parameters to fine-tune your search performance. Whether you’re looking to understand the mechanics or optimize your queries, this exploration of BM25 will equip you with the knowledge to make Elasticsearch work even better for your needs.
What is BM25?
BM25 is a ranking function used to estimate the relevance of documents to a given search query. It’s part of a family of algorithms known as probabilistic information retrieval models, which predict the probability that a given document is relevant to a user’s query.
BM25 is used by default when creating a new index, because it effectively balances various factors that influence relevance, such as the frequency of query terms in a document, the rarity of those terms across the document corpus, and the length of the document.
The BM25 Formula
The core formula for BM25 is as follows:
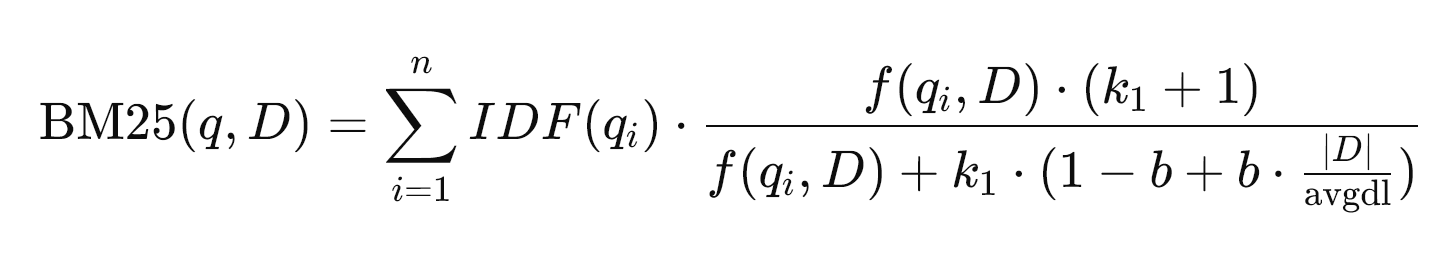
Where:
- q is the query containing n terms.
- D is the document.
- qi is a term in the query.
- f(qi,D) is the frequency of qi in the document D.
- |D| is the length of the document (i.e., the number of words in D).
- avgdl is the average document length in the entire corpus.
- k1 is a tuning parameter that controls term frequency saturation (default value set to 1.2).
- b is a tuning parameter that controls the effect of document length (default value set to 0.75).
- IDF(qi) is the Inverse Document Frequency of the term qi.
Elasticsearch uses a slightly different formula for calculating the Inverse Document Frequency (IDF) than the traditional one. The IDF formula is as follows:
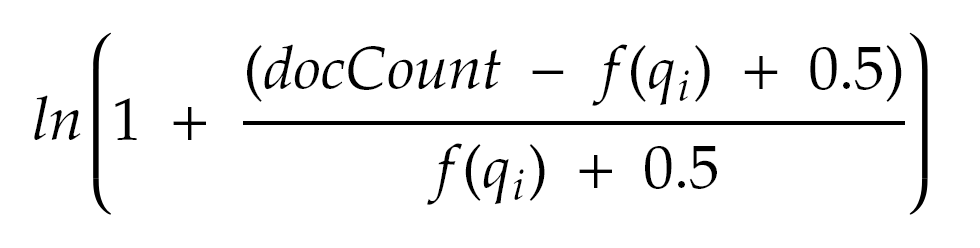
Where:
- docCount is the total number of documents that have a value for the field in the shard (or across all shards if using
search_type=dfs_query_then_fetch). - f(qi) is the number of documents that contain the ith query term.
Breaking Down the BM25 Formula
- Inverse Document Frequency (IDF): The IDF component reduces the influence of very common terms that appear in many documents, giving more weight to rare terms. The more documents a term appears in, the less important it becomes.
- Term Frequency (TF): The term frequency f(qi,D) represents how often a term appears in a document. However, BM25 introduces a saturation effect with the k1 parameter, meaning that the impact of term frequency increases initially but plateaus beyond a certain point.
- Document Length Normalization: The formula includes a normalization factor for document length. The b parameter adjusts how much the length of the document should influence the score. Shorter documents are often more concise, so BM25 balances their length with relevance.
How Elasticsearch Uses BM25
When you submit a query, Elasticsearch breaks it down into individual terms, retrieves documents containing those terms, and then scores each document using the BM25 formula. Documents with higher BM25 scores are ranked higher and are more likely to appear at the top of the search results.
Elasticsearch’s implementation of BM25 is optimized for speed and accuracy, ensuring that search results are both relevant and returned quickly, even when searching through large volumes of data.
Example
Let’s work through an example to see how BM25 would score a document in Elasticsearch. Suppose we have a query for “machine learning” and a document containing the phrase “Machine learning is transforming industries by enabling algorithms to analyze data and make predictions.” which has fourteen words. The average document length in the corpus is twenty, with k1 set to 1.2 and b set to 0.75. The corpus contains 15 documents, with 5 containing the term “machine” and 12 containing the term “learning”. Our focus here will be looking how scoring will work with the document "_id": 12.
Elasticsearch Query Example
In Elasticsearch, BM25 is the default scoring algorithm, but you can influence how it behaves using parameters like k1 and b. Here’s an example of how we can structure an index to adapt search queries in Elasticsearch that uses BM25:
PUT articles
{
"settings": {
"number_of_shards": 1,
"index" : {
"similarity" : {
"default" : {
"type" : "BM25",
"b": 0.75,
"k1": 1.2
}
}
}
}
}
# Documents to use as an example
POST articles/_bulk
{ "index": { "_id": "1" } }
{ "title": "The Future of Renewable Energy", "content": "Renewable energy is the future, with solar and wind leading the charge. Learning to harness these sources efficiently is key." }
{ "index": { "_id": "2" } }
{ "title": "Advancements in Artificial Intelligence", "content": "Artificial intelligence is evolving rapidly recently. Learning from vast datasets, local machines are now capable of complex decision making processes." }
{ "index": { "_id": "3" } }
{ "title": "Understanding Quantum Computing", "content": "Quantum computing is a revolutionary field. Today, learning the principles of quantum mechanics is essential for grasping this machine's potential." }
{ "index": { "_id": "4" } }
{ "title": "The Rise of Online Education", "content": "Today, online education has transformed learning, making it accessible to millions. Platforms offer courses on a wide array of subjects." }
{ "index": { "_id": "5" } }
{ "title": "Machine Learning in Healthcare", "content": "Machine learning is revolutionizing healthcare by analyzing patient data and predicting outcomes as of late, leading to better treatment strategies." }
{ "index": { "_id": "6" } }
{ "title": "The Impact of Climate Change", "content": "Recently, climate change is affecting ecosystems worldwide. Learning about the causes can help us devise strategies to mitigate its impact." }
{ "index": { "_id": "7" } }
{ "title": "Blockchain Technology and Its Applications", "content": "Recently, blockchain technology is changing industries by providing secure, transparent transactions, anonymously. Learning its applications is vital for future innovations." }
{ "index": { "_id": "8" } }
{ "title": "Machine Learning in Finance", "content": "As of recently, machine learning models are increasingly used in finance for risk assessment and algorithmic trading, transforming the industry." }
{ "index": { "_id": "9" } }
{ "title": "Learning Languages with Technology", "content": "Today, technology has made language learning more accessible than ever, with apps, systems and platforms offering personalized and interactive experiences." }
{ "index": { "_id": "10" } }
{ "title": "The Evolution of Machine Learning", "content": "As of today, machine learning has evolved from simple algorithms to complex neural networks, enabling groundbreaking advancements in various fields." }
{ "index": { "_id": "11" } }
{ "title": "Learning Through Virtual Reality", "content": "Virtual reality is changing the way we are learning by providing immersive experiences that enhance understanding and retention of concepts." }
{ "index": { "_id": "12" } }
{ "title": "Transforming Industries with Machine Learning", "content": "Machine learning is transforming industries by enabling algorithms to analyze data and make predictions." }
{ "index": { "_id": "13" } }
{ "title": "The Importance of Mental Health Awareness", "content": "As of recently, Mental health awareness has become increasingly important in today's society. It is crucial to recognize and address mental health issues early." }
{ "index": { "_id": "14" } }
{ "title": "The Role of Renewable Energy in Sustainable Development", "content": "Renewable energy is critical for sustainable development, reducing carbon emissions, and ensuring a healthier environment for future generations to come." }
{ "index": { "_id": "15" } }
{ "title": "The Impact of Social Media on Communication", "content": "Social media has drastically changed the way we communicate, making it easier to stay connected but also creating new challenges." }
In this query, "k1" and "b" are the parameters that control term frequency saturation and document length normalization. To make a search query, the following can be used as example:
{
"query": {
"match": {
"title": "machine learning"
}
}
}
BM25 Calculation
To calculate the BM25 score, we first determine the Inverse Document Frequency (IDF) for “machine” and “learning”, resulting in the image below:
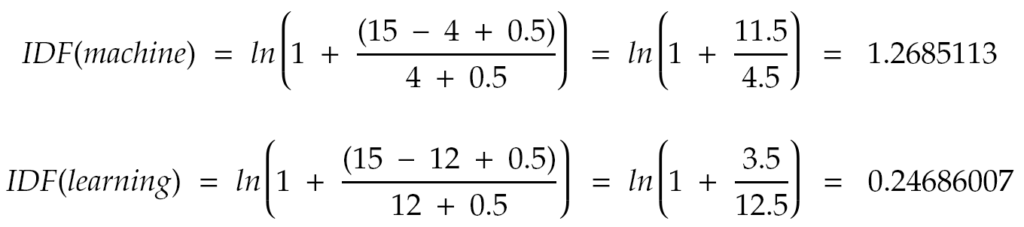
Next, we calculate the term frequency component for both terms, yielding a score of 1.140 for each. Multiplying these components by their respective IDF values:


Finally, sum the BM25 scores for each term, then multiply by the boost to get the overall document score:
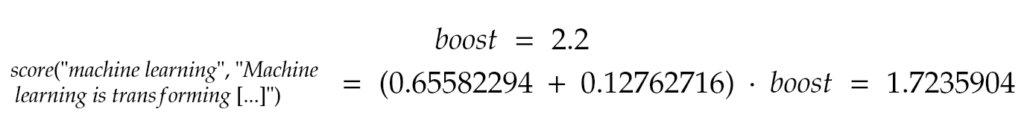
This score would be used to rank the document’s relevance to the query “machine learning”.
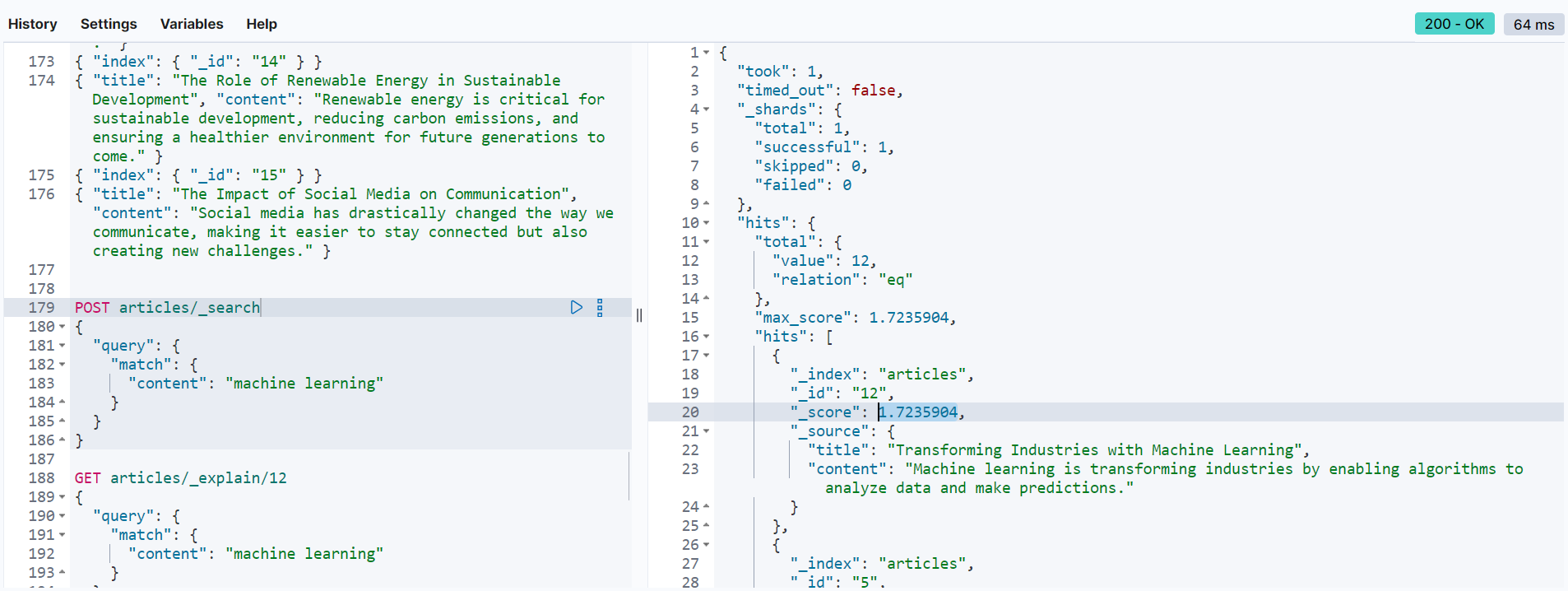
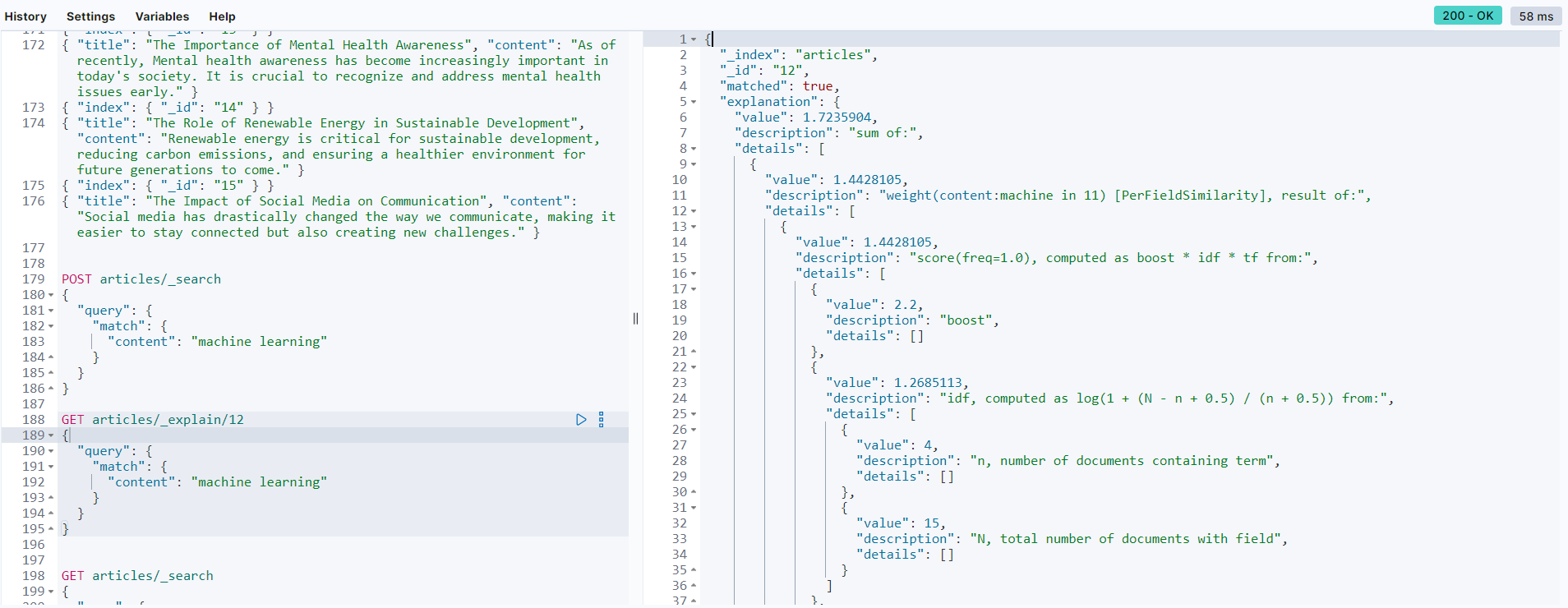
To get more details of the scoring generated on any other document that you may end up making a search query later, you can use index/_explain/_id and receive the exact scores that elasticsearch calculated while retrieving your document:
Conclusion
BM25 is a powerful and flexible ranking algorithm that lies at the heart of Elasticsearch’s search capabilities. By understanding its formula and how it’s applied, you can better appreciate how Elasticsearch determines the relevance of documents and how you can tune your search queries for optimal results.
Whether you’re dealing with large datasets or simply want to fine-tune search results, BM25 provides the foundational scoring mechanism that makes it all possible.